Git 3 - Les branches
Collaborer à l’aide des branches
Nous avons pour l’instant utilisé Git sur une seule branche : nos commits représentent une ligne qui va du commit le plus ancien au commit le plus récent.
Mais la force de Git est le concept d’arborescence (d’arbre) constituée de branches.
Théoriquement, une branche n’est qu’un pointeur vers un commit, une sorte de raccourci vers un commit particulier, qui est mise à jour à chaque fois que l’on crée un nouveau commit sur telle branche.
Créer une branche et basculer sur une branche
Créer une branche se fait avec la sous-commande checkout et l’option -b :
git checkout -b <nom_de_branche>
Si la branche existe déjà, il suffit d’utiliser git checkout suivi du nom de branche :
git checkout <nom_de_branche>
Les tags
- Les tags sont comme des raccourcis vers un commit précis.
- En général on ne les modifie pas après les avoir créés.
- Ils servent souvent pour faire référence au commit précis qui définit la version du code.
Cycles de développement
Il existe plusieurs méthodes d’organisation dans Git par rapport à l’utilité des branches
- parfois il y a une branche
stableet une branchedevelopmentqui représente une version plus beta de l’application - il y a souvent des branches pour chaque fonctionnalité ajoutée, appelées
feature branch
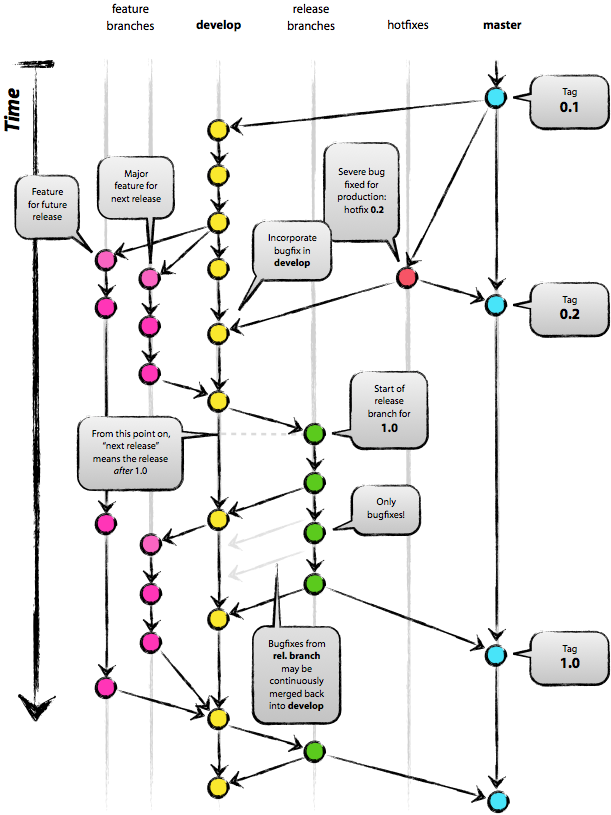 git-flow, le workflow le plus ancien, un peu trop complexe
git-flow, le workflow le plus ancien, un peu trop complexe
L’exemple du GitHub flow
- c’est le Git flow le plus simple, on a :
- une branche
master - des
feature branchpour chaque fonctionnalité en développement
Git pour collaborer…
Merge et rebase
Parfois il faut donc utiliser quelques commandes plus avancées de Git pour expliquer aux gens lisant l’historique Git quand on a voulu raconter que :
- deux versions du code ont été fusionnées (merge, fusion en anglais)
- ou bien des modifications doivent être ajoutées (“rebasées”) sur la dernière version du code (rebase)
Réécrire l’historique
L’historique Git, c’est un peu raconter une histoire de comment on est arrivé à ce bout de code, ajouté pour telle fonctionnalité à telle version du logiciel.
Pour arriver à cela il y a 2 outils importants :
git cherry-pick <commit>: prend un commit et l’ajoute à la branche actuelle- le rebase interactif
Le rebase interactif
Le rebase interactif est un outil un peu compliqué à manipuler, qui nous permet de réécrire l’historique d’une branche en choisissant quels commits on va fusionner ensemble, effacer, ou réordonner. C’est la commande git rebase -i
L’article suivant, extrêmement riche, est une référence à laquelle on peut revenir en cas de doute sur le choix de merge ou de rebase : Bien utiliser Git merge et rebase, par Delicious Insights