0 - Introduction à Docker
Modularisez et maîtrisez vos applications
![]()
Introduction
-
La métaphore docker : “box it, ship it”
-
Une abstraction qui ouvre de nouvelles possibilités pour la manipulation logicielle.
-
Permet de standardiser et de contrôler la livraison et le déploiement.
Retour sur les technologies de virtualisation
On compare souvent les conteneurs aux machines virtuelles. Mais ce sont de grosses simplifications parce qu’on en a un usage similaire : isoler des programmes dans des “contextes”. Une chose essentielle à retenir sur la différence technique : les conteneurs utilisent les mécanismes internes du _kernel de l’OS Linux_ tandis que les VM tentent de communiquer avec l’OS (quel qu’il soit) pour directement avoir accès au matériel de l’ordinateur.
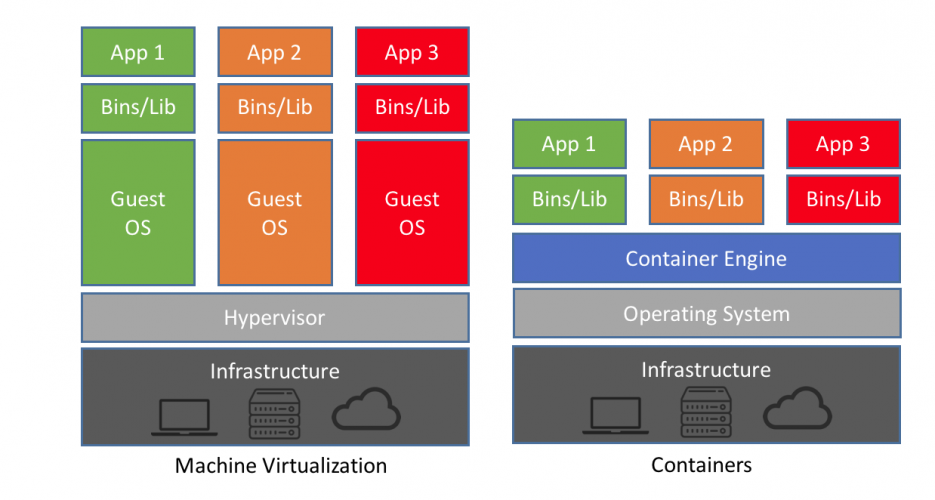
-
VM : une abstraction complète pour simuler des machines
- un processeur, mémoire, appels systèmes, carte réseau, carte graphique, etc.
-
conteneur : un découpage dans Linux pour séparer des ressources (accès à des dossiers spécifiques sur le disque, accès réseau).
Les deux technologies peuvent utiliser un système de quotas pour l’accès aux ressources matérielles (accès en lecture/écriture sur le disque, sollicitation de la carte réseau, du processeur)
Si l’on cherche la définition d’un conteneur :
C’est un groupe de processus associé à un ensemble de permissions.
L’imaginer comme une “boîte” est donc une allégorie un peu trompeuse, car ce n’est pas de la virtualisation (= isolation au niveau matériel).
Docker Origins : genèse du concept de conteneur
Les conteneurs mettent en œuvre un vieux concept d’isolation des processus permis par la philosophie Unix du “tout est fichier”.
chroot, jail, les 6 namespaces et les cgroups
chroot
- Implémenté principalement par le programme
chroot[change root : changer de racine], présent dans les systèmes UNIX depuis longtemps (1979 !) :“Comme tout est fichier, changer la racine d’un processus, c’est comme le faire changer de système”.
jail
-
jailest introduit par FreeBSD en 2002 pour compléterchrootet qui permet pour la première fois une isolation réelle (et sécurisée) des processus. -
chrootne s’occupait que de l’isolation d’un process par rapport au système de fichiers :- ce n’était pas suffisant, l’idée de “tout-est-fichier” possède en réalité plusieurs exceptions
- un process chrooté n’est pas isolé du reste des process et peut agir de façon non contrôlée sur le système sur plusieurs aspects
-
En 2005, Sun introduit les conteneurs Solaris décrits comme un « chroot sous stéroïdes » : comme les jails de FreeBSD
Les namespaces (espaces de noms)
-
Les namespaces, un concept informatique pour parler simplement de…
- groupes séparés auxquels on donne un nom, d’ensembles de choses sur lesquelles on colle une étiquette
- on parle aussi de contextes
-
jailétait une façon de compléterchroot, pour FreeBSD. -
Pour Linux, ce concept est repris via la mise en place de namespaces Linux
- Les namespaces sont inventés en 2002
- popularisés lors de l’inclusion des 6 types de namespaces dans le noyau Linux (3.8) en 2013
-
Les conteneurs ne sont finalement que plein de fonctionnalités Linux saucissonnées ensemble de façon cohérente.
-
Les namespaces correspondent à autant de types de compartiments nécessaires dans l’architecture Linux pour isoler des processus.
Pour la culture, 6 types de namespaces :
- Les namespaces PID : “fournit l’isolation pour l’allocation des identifiants de processus (PIDs), la liste des processus et de leurs détails. Tandis que le nouvel espace de nom est isolé de ses adjacents, les processus dans son espace de nommage « parent » voient toujours tous les processus dans les espaces de nommage enfants — quoique avec des numéros de PID différent.”
- Network namespace : “isole le contrôleur de l’interface réseau (physique ou virtuel), les règles de pare-feu iptables, les tables de routage, etc.”
- Mount namespace : “permet de créer différents modèles de systèmes de fichiers, ou de créer certains points de montage en lecture-seule”
- User namespace : isolates the user IDs between namespaces (dernière pièce du puzzle)
- “UTS” namespace : permet de changer le nom d’hôte.
- IPC namespace : isole la communication inter-processus entre les espaces de nommage.
Les cgroups : derniers détails pour une vraie isolation
-
Après, il reste à s’occuper de limiter la capacité d’un conteneur à agir sur les ressources matérielles :
- usage de la mémoire
- du disque
- du réseau
- des appels système
- du processeur (CPU)
-
En 2005, Google commence le développement des cgroups : une façon de tagger les demandes de processeur et les appels systèmes pour les grouper et les isoler.
Exemple : bloquer le système hôte depuis un simple conteneur
:(){ : | :& }; :
Ceci est une fork bomb. Dans un conteneur non privilégié, on bloque tout Docker, voire tout le système sous-jacent, en l’empêchant de créer de nouveaux processus.
Pour éviter cela il faudrait limiter la création de processus via une option kernel.
Ex: docker run -it --ulimit nproc=3 --name fork-bomb bash
L’isolation des conteneurs n’est donc ni magique, ni automatique, ni absolue ! Correctement paramétrée, elle est tout de même assez robuste, mature et testée.
Les conteneurs : définition
On revient à notre définition d’un conteneur :
Un conteneur est un groupe de processus associé à un ensemble de permissions sur le système.
1 container = 1 groupe de process Linux
- des namespaces (séparation entre ces groups)
- des cgroups (quota en ressources matérielles)
LXC (LinuX Containers)
-
En 2008 démarre le projet LXC qui chercher à rassembler :
- les cgroups
- le chroot
- les namespaces.
-
Originellement, Docker était basé sur LXC. Il a depuis développé son propre assemblage de ces 3 mécanismes.
Docker et LXC
-
En 2013, Docker commence à proposer une meilleure finition et une interface simple qui facilite l’utilisation des conteneurs LXC.
-
Puis il propose aussi son cloud, le Docker Hub pour faciliter la gestion d’images toutes faites de conteneurs.
-
Au fur et à mesure, Docker abandonne le code de LXC (mais continue d’utiliser le chroot, les cgroups et namespaces).
-
Le code de base de Docker (notamment runC) est open source : l'Open Container Initiative vise à standardiser et rendre robuste l’utilisation de containers.
Bénéfices par rapport aux machines virtuelles
Docker permet de faire des “quasi-machines” avec des performances proches du natif.
- Vitesse d’exécution.
- Flexibilité sur les ressources (mémoire partagée).
- Moins complexe que la virtualisation
- Plus standard que les multiples hyperviseurs
- notamment moins de bugs d’interaction entre l’hyperviseur et le noyau
Bénéfices par rapport aux machines virtuelles
VM et conteneurs proposent une flexibilité de manipulation des ressources de calcul mais les machines virtuelles sont trop lourdes pour être multipliées librement :
- elles ne sont pas efficaces pour isoler chaque application
- elles ne permettent pas la transformation profonde que permettent les conteneurs :
- le passage à une architecture microservices
- et donc la scalabilité pour les besoins des services cloud
Avantages des machines virtuelles
-
Les VM se rapprochent plus du concept de “boite noire”: l’isolation se fait au niveau du matériel et non au niveau du noyau de l’OS.
-
même si une faille dans l’hyperviseur reste possible car l’isolation n’est pas qu’uniquement matérielle
-
Les VM sont-elles “plus lentes” ? Pas forcément.
- La RAM est-elle un facteur limite ? Non elle n’est pas cher
- Les CPU pareil : on est rarement bloqués par la puissance du CPU
- Le vrai problème c’est l’I/O : l’accès en entrée-sortie au disque et au réseau
- en réalité Docker peut être bien plus lent pour l’implémentation de la sécurité réseau (usage du NAT et du bridging)
- pareil pour l’accès au disque : la technologie d'overlay (qui a une place centrale dans Docker) s’améliore mais reste lente.
La comparaison VM / conteneurs est un thème extrêmement vaste et complexe.
Pourquoi utiliser Docker ?
Docker est pensé dès le départ pour faire des conteneurs applicatifs :
-
isoler les modules applicatifs.
-
gérer les dépendances en les embarquant dans le conteneur.
-
se baser sur l'immutabilité : la configuration d’un conteneur n’est pas faite pour être modifiée après sa création.
-
avoir un cycle de vie court -> logique DevOps du “bétail vs. animal de compagnie”
Pourquoi utiliser Docker ?
Docker modifie beaucoup la “logistique” applicative.
-
uniformisation face aux divers langages de programmation, configurations et briques logicielles
-
installation sans accroc et automatisation beaucoup plus facile
-
permet de simplifier l'intégration continue, la livraison continue et le déploiement continu
-
rapproche le monde du développement des opérations (tout le monde utilise la même technologie)
-
Permet l’adoption plus large de la logique DevOps (notamment le concept d’infrastructure as code)
Infrastructure as Code
Résumé
- on décrit en mode code un état du système. Avantages :
- pas de dérive de la configuration et du système (immutabilité)
- on peut connaître de façon fiable l’état des composants du système
- on peut travailler en collaboration plus facilement (grâce à Git notamment)
- on peut faire des tests
- on facilite le déploiement de nouvelles instances
Docker : positionnement sur le marché
-
Docker est la technologie ultra-dominante sur le marché de la conteneurisation
- La simplicité d’usage et le travail de standardisation (un conteneur Docker est un conteneur OCI : format ouvert standardisé par l’Open Container Initiative) lui garantissent légitimité et fiabilité
- La logique du conteneur fonctionne, et la bonne documentation et l’écosystème aident !
-
LXC existe toujours et est très agréable à utiliser, notamment avec LXD (développé par Canonical, l’entreprise derrière Ubuntu).
- Il a cependant un positionnement différent : faire des conteneurs pour faire tourner des OS Linux complets.
-
Apache Mesos : un logiciel de gestion de cluster qui permet de se passer de Docker, mais propose quand même un support pour les conteneurs OCI (Docker) depuis 2016.
-
Podman : une alternative à Docker qui utilise la même syntaxe que Docker pour faire tourner des conteneurs OCI (Docker) qui propose un mode rootless et daemonless intéressant.
-
systemd-nspawn : technologie de conteneurs isolés proposée par systemd