04 - Cours - Objets Kubernetes - Partie 1
L’API et les Objets Kubernetes
Utiliser Kubernetes consiste à déclarer des objets grâce à l’API Kubernetes pour décrire l’état souhaité d’un cluster : quelles applications ou autres processus exécuter, quelles images elles utilisent, le nombre de replicas, les ressources réseau et disque que vous mettez à disposition, etc.
On définit des objets généralement via l’interface en ligne de commande et kubectl de deux façons :
- en lançant une commande
kubectl run <conteneur> ...,kubectl expose ... - en décrivant un objet dans un fichier YAML ou JSON et en le passant au client
kubectl apply -f monpod.yml
Vous pouvez également écrire des programmes qui utilisent directement l’API Kubernetes pour interagir avec le cluster et définir ou modifier l’état souhaité. Kubernetes est complètement automatisable !
La commande apply
Kubernetes encourage le principe de l’infrastructure-as-code : il est recommandé d’utiliser une description YAML et versionnée des objets et configurations Kubernetes plutôt que la CLI.
Pour cela la commande de base est kubectl apply -f object.yaml.
La commande inverse kubectl delete -f object.yaml permet de détruire un objet précédement appliqué dans le cluster à partir de sa description.
Lorsqu’on vient d’appliquer une description on peut l’afficher dans le terminal avec kubectl apply -f myobj.yaml view-last-applied
Globalement Kubernetes garde un historique de toutes les transformations des objets : on peut explorer, par exemple avec la commande kubectl rollout history deployment.
Parenthèse : Le YAML
Kubernetes décrit ses ressources en YAML. A quoi ça ressemble, YAML ?
- marché:
lieu: Marché de la Place
jour: jeudi
horaire:
unité: "heure"
min: 12
max: 20
fruits:
- nom: pomme
couleur: "verte"
pesticide: avec
- nom: poires
couleur: jaune
pesticide: sans
légumes:
- courgettes
- salade
- potiron
Syntaxe
-
Alignement ! (2 espaces !!)
-
ALIGNEMENT !! (comme en python)
-
ALIGNEMENT !!! (le défaut du YAML, pas de correcteur syntaxique automatique, c’est bête mais vous y perdrez forcément du temps !)
-
des listes (tirets)
-
des paires clé: valeur
-
Un peu comme du JSON, avec cette grosse différence que le JSON se fiche de l’alignement et met des accolades et des points-virgules
-
les extensions Kubernetes et YAML dans VSCode vous aident à repérer des erreurs
Syntaxe de base d’une description YAML Kubernetes
Les description YAML permettent de décrire de façon lisible et manipulable de nombreuses caractéristiques des ressources Kubernetes (un peu comme un Compose file par rapport à la CLI Docker).
Exemple
Création d’un service simple :
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
type: NodePort
Remarques de syntaxe :
- Toutes les descriptions doivent commencer par spécifier la version d’API (minimale) selon laquelle les objets sont censés être créés
- Il faut également préciser le type d’objet avec
kind - Le nom dans
metadata:\n name: valueest également obligatoire. - On rajoute généralement une description longue démarrant par
spec:
Description de plusieurs ressources
-
On peut mettre plusieurs ressources à la suite dans un fichier k8s : cela permet de décrire une installation complexe en un seul fichier
- par exemple le dashboard Kubernetes https://github.com/kubernetes/dashboard/blob/master/aio/deploy/recommended.yaml
-
L’ordre n’importe pas car les ressources sont décrites déclarativement c’est-à-dire que:
- Les dépendances entre les ressources sont déclarées
- Le control plane de Kubernetes se charge de planifier l’ordre correct de création en fonction des dépendances (pods avant le déploiement, rôle avec l’utilisateur lié au rôle)
- On préfère cependant les mettre dans un ordre logique pour que les humains puissent les lire.
-
On peut sauter des lignes dans le YAML et rendre plus lisible les descriptions
-
On sépare les différents objets par
---
Objets de base
Les namespaces
Tous les objets Kubernetes sont rangés dans différents espaces de travail isolés appelés namespaces.
Cette isolation permet 3 choses :
- ne voir que ce qui concerne une tâche particulière (ne réfléchir que sur une seule chose lorsqu’on opère sur un cluster)
- créer des limites de ressources (CPU, RAM, etc.) pour le namespace
- définir des rôles et permissions sur le namespace qui s’appliquent à toutes les ressources à l’intérieur.
Lorsqu’on lit ou créé des objets sans préciser le namespace, ces objets sont liés au namespace default.
Pour utiliser un namespace autre que default avec kubectl il faut :
- le préciser avec l’option
-n:kubectl get pods -n kube-system - créer une nouvelle configuration dans la kubeconfig pour changer le namespace par defaut.
Kubernetes gère lui-même ses composants internes sous forme de pods et services.
- Si vous ne trouvez pas un objet, essayez de lancer la commande kubectl avec l’option
-Aou--all-namespaces
Les Pods
Un Pod est l’unité d’exécution de base d’une application Kubernetes que vous créez ou déployez. Un Pod représente des process en cours d’exécution dans votre Cluster.
Un Pod encapsule un conteneur (ou souvent plusieurs conteneurs), des ressources de stockage, une IP réseau unique, et des options qui contrôlent comment le ou les conteneurs doivent s’exécuter (ex: restart policy). Cette collection de conteneurs et volumes tournent dans le même environnement d’exécution mais les processus sont isolés.
Un Pod représente une unité de déploiement : un petit nombre de conteneurs qui sont étroitement liés et qui partagent :
- les mêmes ressources de calcul
- des volumes communs
- la même IP donc le même nom de domaine
- peuvent se parler sur localhost
- peuvent se parler en IPC
- ont un nom différent et des logs différents
Chaque Pod est destiné à exécuter une instance unique d’un workload donné. Si vous désirez mettre à l’échelle votre workload, vous devez multiplier le nombre de Pods avec un déploiement.
Pour plus de détail sur la philosophie des pods, vous pouvez consulter ce bon article.
Kubernetes fournit un ensemble de commande pour débugger des conteneurs :
kubectl logs <pod-name> -c <conteneur_name>(le nom du conteneur est inutile si un seul)kubectl exec -it <pod-name> -c <conteneur_name> -- bashkubectl attach -it <pod-name>
Enfin, pour debugger la sortie réseau d’un programme on peut rapidement forwarder un port depuis un pods vers l’extérieur du cluster :
kubectl port-forward <pod-name> <port_interne>:<port_externe>- C’est une commande de debug seulement : pour exposer correctement des processus k8s, il faut créer un service, par exemple avec
NodePort.
Pour copier un fichier dans un pod on peut utiliser: kubectl cp <pod-name>:</path/to/remote/file> </path/to/local/file>
Pour monitorer rapidement les ressources consommées par un ensemble de processus il existe les commande kubectl top nodes et kubectl top pods
Un manifeste de Pod
rancher-demo-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: rancher-demo-pod
spec:
containers:
- image: monachus/rancher-demo:latest
name: rancher-demo-container
ports:
- containerPort: 8080
name: http
protocol: TCP
- image: redis
name: redis-container
ports:
- containerPort: 6379
name: http
protocol: TCP
Rappel sur quelques concepts
Haute disponibilité
- Faire en sorte qu’un service ait un “uptime” élevé.
On veut que le service soit tout le temps accessible même lorsque certaines ressources manquent :
- elles tombent en panne
- elles sont sorties du service pour mise à jour, maintenance ou modification
Pour cela on doit avoir des ressources multiples…
- Plusieurs serveurs
- Plusieurs versions des données
- Plusieurs accès réseau
Il faut que les ressources disponibles prennent automatiquement le relais des ressources indisponibles. Pour cela on utilise en particulier:
- des “load balancers” : aiguillages réseau intelligents
- des “healthchecks” : une vérification de la santé des applications
Nous allons voir que Kubernetes intègre automatiquement les principes de load balancing et de healthcheck dans l’orchestration de conteneurs
Répartition de charge (load balancing)
- Un load balancer : une sorte d'“aiguillage” de trafic réseau, typiquement HTTP(S) ou TCP.
- Un aiguillage intelligent qui se renseigne sur plusieurs critères avant de choisir la direction.
Cas d’usage :
- Éviter la surcharge : les requêtes sont réparties sur différents backends pour éviter de les saturer.
L’objectif est de permettre la haute disponibilité : on veut que notre service soit toujours disponible, même en période de panne/maintenance.
-
Donc on va dupliquer chaque partie de notre service et mettre les différentes instances derrière un load balancer.
-
Le load balancer va vérifier pour chaque backend s’il est disponible (healthcheck) avant de rediriger le trafic.
-
Répartition géographique : en fonction de la provenance des requêtes on va rediriger vers un datacenter adapté (+ proche).
Healthchecks
Fournir à l’application une façon d’indiquer qu’elle est disponible, c’est-à-dire :
- qu’elle est démarrée (liveness)
- qu’elle peut répondre aux requêtes (readiness).
Application microservices
-
Une application composée de nombreux petits services communiquant via le réseau. Le calcul pour répondre à une requête est décomposé en différente parties distribuées entre les services. Par exemple:
-
un service est responsable de la gestion des clients et un autre de la gestion des commandes.
-
Ce mode de développement implique souvent des architectures complexes pour être mis en oeuvre et kubernetes est pensé pour faciliter leur gestion à grande échelle.
-
Imaginez devoir relancer manuellement des services vitaux pour une application en hébergeant des centaines d’instances : c’est en particulier à ce moment que kubernetes devient indispensable.
2 exemples d’application microservices:
- https://github.com/microservices-patterns/ftgo-application -> fonctionne avec le très bon livre
Microservices patternvisible sur le readme. - https://github.com/GoogleCloudPlatform/microservices-demo -> Exemple d’application microservice de référence de Google pour Kubernetes.
L’architecture découplée des services Kubernetes
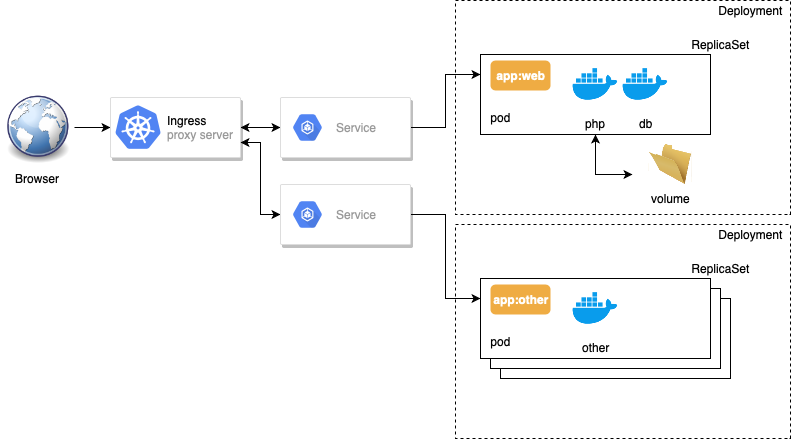
Comme nous l’avons vu dans le TP1, déployer une application dans kubernetes demande plusieurs étapes. En réalité en plus des pods l’ensemble de la gestion d’un service applicatif se décompose dans Kubernetes en 3 à 4 objets articulés entre eux:
- replicatset
- deployment
- service
- (ingress)
Les Deployments (deploy)
Les déploiements sont les objets effectivement créés manuellement lorsqu’on déploie une application. Ce sont des objets de plus haut niveau que les pods et replicaset et les pilote pour gérer un déploiement applicatif.
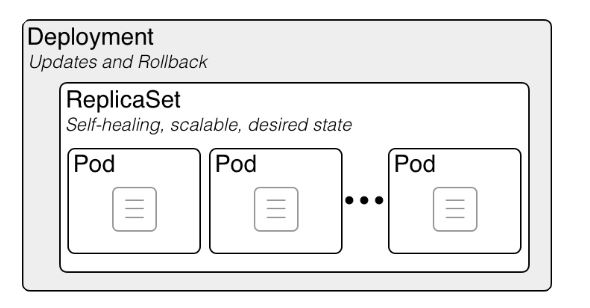 Les poupées russes Kubernetes : un Deployment contient un ReplicaSet, qui contient des Pods, qui contiennent des conteneurs
Les poupées russes Kubernetes : un Deployment contient un ReplicaSet, qui contient des Pods, qui contiennent des conteneurs
Si c’est nécessaire d’avoir ces trois types de ressources c’est parce que Kubernetes respecte un principe de découplage des responsabilités.
La responsabilité d’un déploiement est de gérer la coexistence et le tracking de versions multiples d’une application et d’effectuer des montées de version automatiques en haute disponibilité en suivant une RolloutStrategy (CF. TP optionnel).
Ainsi lors des changements de version, un seul deployment gère automatiquement deux replicasets contenant chacun une version de l’application : le découplage est nécessaire.
Un deployment implique la création d’un ensemble de Pods désignés par une étiquette label et regroupé dans un Replicaset.
Exemple :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
strategy:
type: Recreate
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
-
Pour les afficher :
kubectl get deployments -
La commande
kubectl runsert à créer un deployment à partir d’un modèle. Il vaut mieux utilisezapply -f.
Les ReplicaSets (rs)
Dans notre modèle, les ReplicaSet servent à gérer et sont responsables pour:
-
la réplication (avoir le bon nombre d’instances et le scaling)
-
la santé et le redémarrage automatique des pods de l’application (Self-Healing)
-
kubectl get rspour afficher la liste des replicas.
En général on ne les manipule pas directement (c’est déconseillé) même s’il est possible de les modifier et de les créer avec un fichier de ressource. Pour créer des groupes de conteneurs on utilise soit un Deployment soit d’autres formes de workloads (DaemonSet, StatefulSet, Job) adaptés à d’autres cas.
Les Services
Dans Kubernetes, un service est un objet qui :
- Désigne un ensemble de pods (grâce à des tags) généralement géré par un déploiement.
- Fournit un endpoint réseau pour les requêtes à destination de ces pods.
- Configure une politique permettant d’y accéder depuis l’intérieur ou l’extérieur du cluster.
L’ensemble des pods ciblés par un service est déterminé par un selector.
Par exemple, considérons un backend de traitement d’image (stateless, c’est-à-dire ici sans base de données) qui s’exécute avec 3 replicas. Ces replicas sont interchangeables et les frontends ne se soucient pas du backend qu’ils utilisent. Bien que les pods réels qui composent l’ensemble backend puissent changer, les clients frontends ne devraient pas avoir besoin de le savoir, pas plus qu’ils ne doivent suivre eux-mêmes l’état de l’ensemble des backends.
L’abstraction du service permet ce découplage : les clients frontend s’addressent à une seule IP avec un seul port dès qu’ils ont besoin d’avoir recours à un backend. Les backends vont recevoir la requête du frontend aléatoirement.
Les Services sont de trois types principaux :
-
ClusterIP: expose le service sur une IP interne au cluster. Les autres pods peuvent alors accéder au service de l’intérieur du cluster, mais il n’est pas l’extérieur. -
NodePort: expose le service depuis l’IP de chacun des noeuds du cluster en ouvrant un port directement sur le nœud, entre 30000 et 32767. Cela permet d’accéder aux pods internes répliqués. Comme l’IP est stable on peut faire pointer un DNS ou Loadbalancer classique dessus.
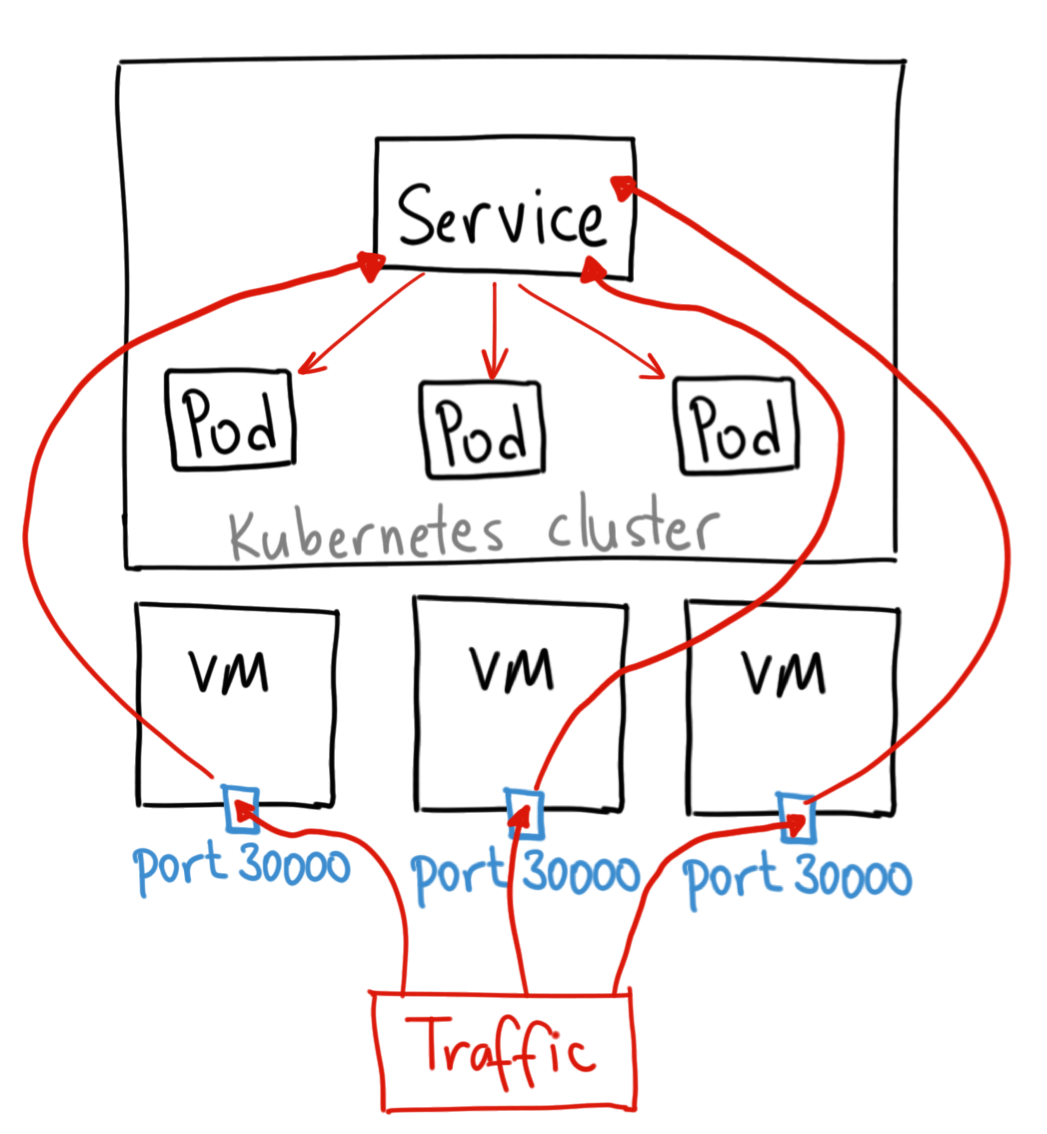 Crédits à Ahmet Alp Balkan pour les schémas
Crédits à Ahmet Alp Balkan pour les schémas
LoadBalancer: expose le service en externe à l’aide d’un Loadbalancer de fournisseur de cloud. Les services NodePort et ClusterIP, vers lesquels le Loadbalancer est dirigé sont automatiquement créés.
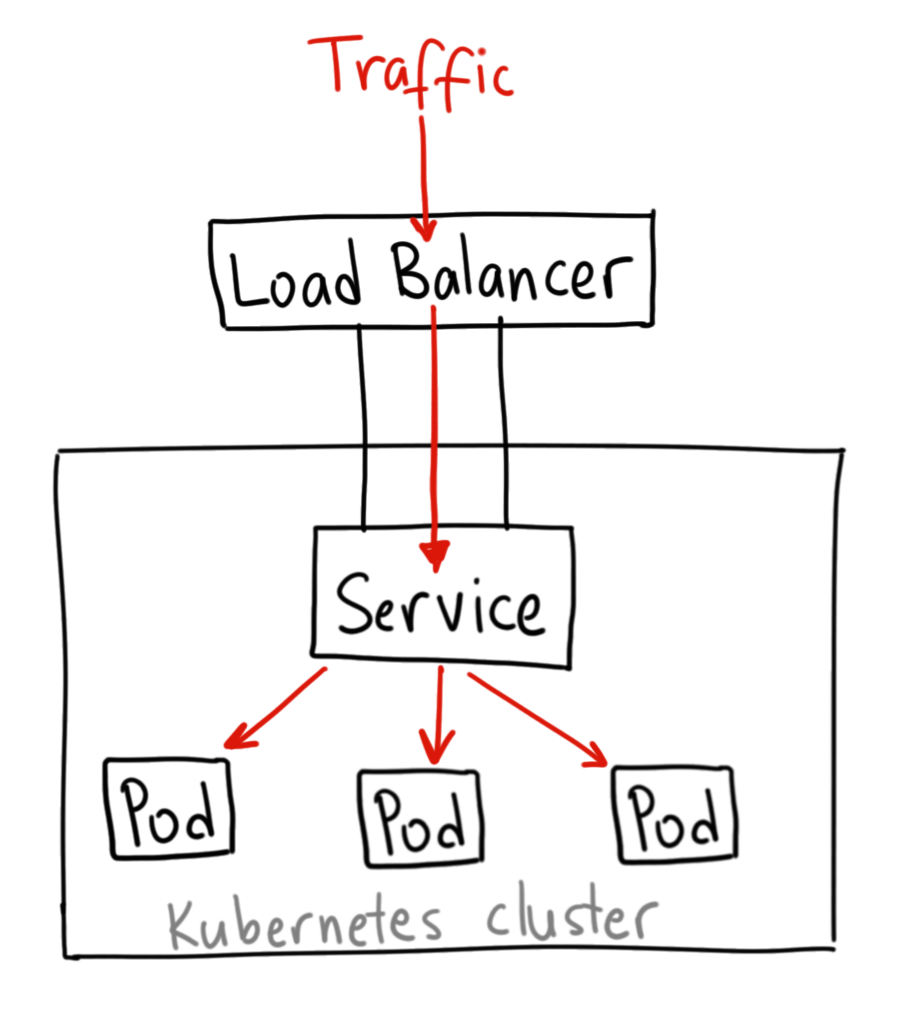 Crédits Ahmet Alp Balkan
Crédits Ahmet Alp Balkan
Les autres types de Workloads Kubernetes
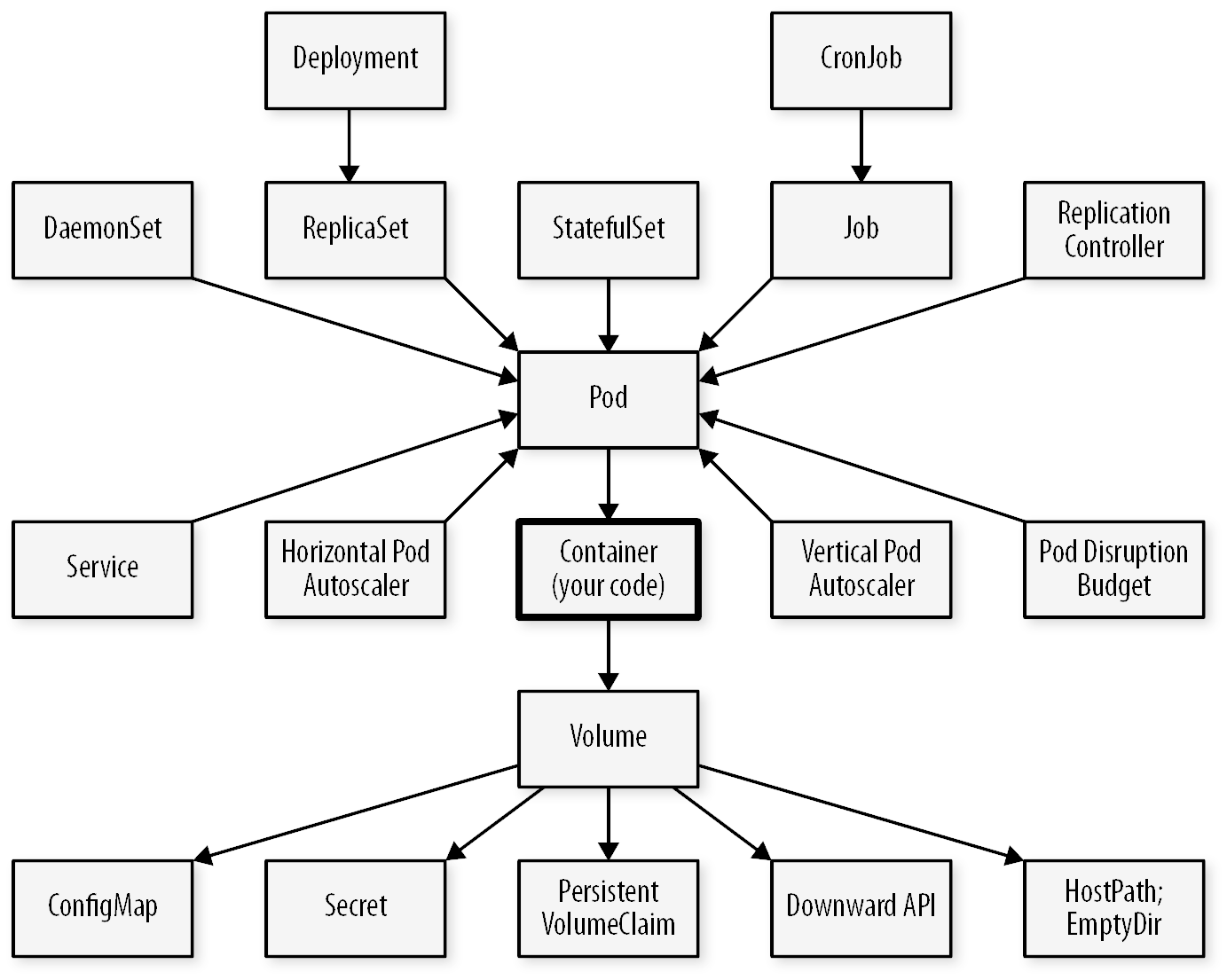
En plus du déploiement d’un application, Il existe pleins d’autre raisons de créer un ensemble de Pods:
- Le DaemonSet: Faire tourner un agent ou démon sur chaque nœud, par exemple pour des besoins de monitoring, ou pour configurer le réseau sur chacun des nœuds.
- Le Job : Effectuer une tache unique de durée limitée et ponctuelle, par exemple de nettoyage d’un volume ou la préparation initiale d’une application, etc.
- Le CronJob : Effectuer une tache unique de durée limitée et récurrente, par exemple de backup ou de régénération de certificat, etc.
De plus même pour faire tourner une application, les déploiements ne sont pas toujours suffisants. En effet ils sont peu adaptés à des applications statefull comme les bases de données de toutes sortes qui ont besoin de persister des données critiques. Pour celà on utilise un StatefulSet que nous verrons par la suite.
Étant donné les similitudes entre les DaemonSets, les StatefulSets et les Deployments, il est important de comprendre un peu précisément quand les utiliser.
Les Deployments (liés à des ReplicaSets) doivent être utilisés :
- lorsque votre application est complètement découplée du nœud
- que vous pouvez en exécuter plusieurs copies sur un nœud donné sans considération particulière
- que l’ordre de création des replicas et le nom des pods n’est pas important
- lorsqu’on fait des opérations stateless
Les DaemonSets doivent être utilisés :
- lorsqu’au moins une copie de votre application doit être exécutée sur tous les nœuds du cluster (ou sur un sous-ensemble de ces nœuds).
Les StatefulSets doivent être utilisés :
- lorsque l’ordre de création des replicas et le nom des pods est important
- lorsqu’on fait des opérations stateful (écrire dans une base de données)
Jobs
Les jobs sont utiles pour les choses que vous ne voulez faire qu’une seule fois, comme les migrations de bases de données ou les travaux par lots. Si vous exécutez une migration en tant que Pod dans un deployment:
- Dès que la migration se finit le processus du pod s’arrête.
- Le replicaset qui détecte que l'“application” s’est arrêter va tenter de la redémarrer en recréant le pod.
- Votre tâche de migration de base de données se déroulera donc en boucle, en repeuplant continuellement la base de données.
CronJobs
Comme des jobs, mais se lancent à un intervalle régulier, comme les cron sur les systèmes unix.